





En matière de détection de corps humains dans un espace, les technologies existantes présentent des failles majeures, que des chercheurs ont tenté de combler avec la technologie DensePose from Wifi.
Dépasser les technologies traditionnelles
Dans le domaine de la détection et de la modélisation 3D de corps humains dans un espace, des technologies comme les LiDAR, radars et caméras RVB sont déjà largement répandues auprès du grand public. La nouvelle technique DensePose from wifi s’inspire de ses prédécesseurs et veut combler leurs limites à travers l’usage des signaux WiFi.
Avant de plonger au cœur de cette approche alternative de la détection humaine, un petit tour d’horizon des technologies de détection populaires s’impose.
DensePose pour prédire les poses humaines
Via l’utilisation d’un réseau neuronal profond et sur la base d’une image 2D en RVB, la technologie DensePose prédit déjà en temps réel de nombreuses poses malgré la présence d’objets occultants. Cette technologie prend pour donnée d’entrée une image RVB et se trouve moins performante dans des contextes de pénombre ou d’éblouissement. De plus, le champ étroit des caméras ne favorise pas non plus une détection optimale.
Radar de type FMCW et RF-Pose
Le radar de type FMCW repose sur la différence de fréquence entre les signaux radar reçus et émis pour localiser une cible. Sa version améliorée RF-Pose s’appuie sur les signaux sans fil dans les fréquences WiFi et sur une approche de réseau neuronal profond, rendant possible la détection de formes humaines en mouvement à travers un obstacle occultant. Le coût élevé de son équipement spécialisé constitue malgré tout un frein majeur.
Modélisation 3D des corps humains avec MmMesh
Basée sur les ondes millimétriques MM Waves, la solution MmMesh génère en temps réel une modélisation 3D des corps humains. Néanmoins les ondes en question ne pénètrent pas les objets, ce qui limite son fonctionnement en cas d’encombrement de la scène observée.
D’emblée, nous voyons l’intérêt de DensePose from WiFi, qui effectue un rendu 3D du maillage des corps, avec pour données d’entrée des ondes WiFi et dont le fonctionnement est optimisé avec l’aide du réseau neuronal de DensePose. Ce faisant, DensePose from WiFi dépasse les limites liées à la photosensibilité des caméras RVB et l’impossibilité à prédire une pose en cas d’obstruction visuelle. Son installation se trouve également bien moins coûteuse dans la mesure où les routeurs WiFi sont déjà présents dans de nombreux foyers, et bien moins énergivores que les solutions LiDAR et radars.
Fonctionnement en détails de cette nouvelle technologie
Exploitation des informations d’état du canal (CSI)
Avec trois émetteurs WiFi et trois récepteurs alignés, les chercheurs récupèrent une correspondance dense de la pose humaine et ce, dans des scénarios comprenant plusieurs sujets et des objets occultants.
Pour fonctionner, la perception via WiFi repose sur les informations d’état du canal (CSI), soit le rapport entre l’onde du signal émis et l’onde du signal reçu, et doit prendre en compte plusieurs paramètres. Les CSI se traduisent par des séquences décimales complexes, qui ne correspondent cependant pas aux emplacements spatiaux, comme les pixels d’une image. De plus, la précision de localisation elle-même se trouve réduite à 0,5 mètres, du fait du déphasage aléatoire autorisé par la norme de communication WiFi IEEE 802.11n/ac. Le dernier paramètre non négligeable réside dans les interférences que peuvent causer les autres appareils électroniques fonctionnant sur la même gamme de fréquence, tels que les fours à micro-ondes ou les téléphones portables.
Ainsi, pour corriger les informations incorrectes communiquées par le Channel State Information, une méthode bien précise est appliquée, avec l’ajout de plusieurs couches de précision et l’intervention du Deep Learning.

Cartes UV à partir des signaux wifi
L’approche DensePose basé sur le wifi WiFi se traduit tout d’abord par la production de coordonnées UV de la surface du corps humain à partir des signaux Wifi. Pour cela, trois composants sont exploités : Les signaux CSI bruts sont traités par nettoyage de l’amplitude et de la phase. Ensuite, à partir des échantillons CSI nettoyés, un réseau codeur-décodeur à deux branches convertit la plage en cartes de caractéristiques 2D semblables à des images. Les caractéristiques 2D sont ensuite transmises à une architecture DensePose-RCNN modifiée pour estimer la carte UV.
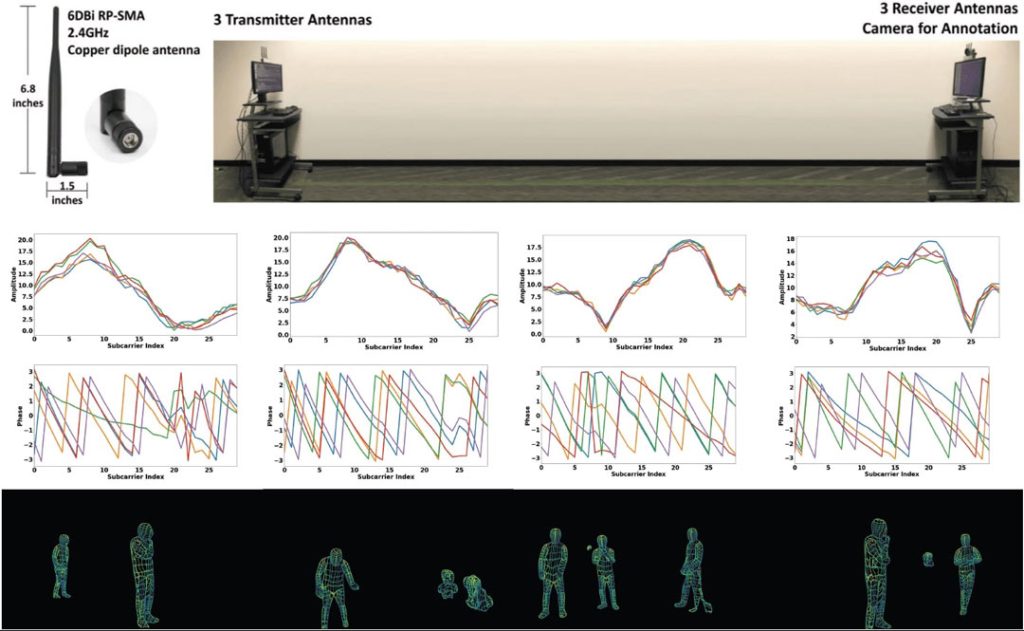
Ajout de couches d’apprentissage avec le deep learning
Les premières détections manquant de précisions au niveau des détails du corps, tels que les membres, l’ajout d’une couche d’entraînement via les points clés a été ajoutée. DensePose from WiFi étant dotée d’une structure de réseau similaire à celle du DensePose-RCNN, l’étape supplémentaire d’entraînement permet d’empêcher les prédictions DensePose de s’éloigner significativement des articulations du corps humain.
Pour pousser l’optimisation du processus, l’entraînement du nouveau modèle se voit supervisé par le réseau pré entraîné basé sur l’image. Cela est rendu possible par l’apprentissage par transfert, via la formation initiale d’un modèle DensePose-RCNN basé sur l’image comme réseau enseignant. Pour ce faire, les chercheurs règlent le poids du réseau enseignant, puis, entraînent le réseau d’entrée WiFi avec les images synchronisées et les tenseurs CSI, respectivement.
L’apprentissage par transfert a pour objectif de minimiser les différences entre les cartes de caractéristiques multi-niveaux générées par le modèle du réseau enseignant et celles générées par le modèle apprenant, et de facto de réduire le temps d’entraînement de ce dernier.
Des failles amoindries mais toujours présentes
La performance de DensePose from WiFi se montre très prometteuse. Elle prouve que l’exploitation des signaux WiFi offre plus de capacité d’estimation de pose dense que les technologies radar, LiDAR et caméra RVB, et se trouvent plus abordables financièrement.
Le rapport des chercheurs met cependant en avant deux problématiques.
Premièrement, les chercheurs font état d’un biais dont souffrait le modèle par les images et qui s’est reproduit durant les expérimentations conduites sur le nouveau modèle. Il s’agit de l’observation d’une baisse de performances sur un même protocole de disposition. Il serait question ici d’une problématique de généralisation, qui devrait être atténuée par un ensemble de données plus complet provenant d’un éventail de contextes plus large.

Deuxièmement, si les auteurs affirment de leur technologie qu’elle respecte la vie prie, dans les faits, cela reste discutable. Effectivement, les technologies se basant sur de la détection visuelle posent un problème évident de confidentialité, notamment dans le domaine de la santé, dans la mesure où les patients âgés sont de plus en plus soignés à leur domicile et en demande d’autonomie, et pour qui ces technologies de surveillance deviennent des outils d’assistance. La possibilité de se passer d’images pour surveiller un individu constitue pour les chercheurs un réel avantage car seuls les maillages 3D d’une personne sont observables. En cas de comportement jugé anormal par le modèle, celui-ci pourrait alors donner l’alerte. La question de la singularité peut se poser ici : cela peut être rapidement stigmatisant si le modèle n’est pas entraîné à reconnaître des comportements singuliers d’individus qui n’ont pourtant pas besoin d’assistance. Sans aller aussi loin, la confidentialité reste considérablement altérée dans certaines situations domestiques. Par exemple, si l’on est capable de déterminer la position assise d’un individu, il est tout à fait possible d’imaginer l’action de cette personne en temps réel dans un espace intime.
Évidemment, cette solution employée dans un usage militaire offrirait de nouvelles approches de surveillance. Dans l’exemple de la détection d’un individu armé, une confirmation visuelle pourrait cependant être nécessaire et intervenir en support pour s’assurer qu’il ne s’agit pas simplement d’un civil prenant une pose qui prêterait à confusion.



