





Les technologies de l’intelligence artificielle et du machine learning (ML) sont devenues des éléments clés dans les domaines de la recherche, de la finance, et de la santé. Cependant, un rapport récent a mis en lumière des failles de sécurité dans certains des frameworks ML les plus utilisés. Ces vulnérabilités compromettent non seulement les données, mais aussi la fiabilité des modèles eux-mêmes. Dans cet article, nous analyserons les implications de ces failles, les risques associés et les mesures que les entreprises et les chercheurs peuvent prendre pour sécuriser leurs systèmes d’apprentissage automatique.
Quelles sont les failles découvertes dans les frameworks ML ?
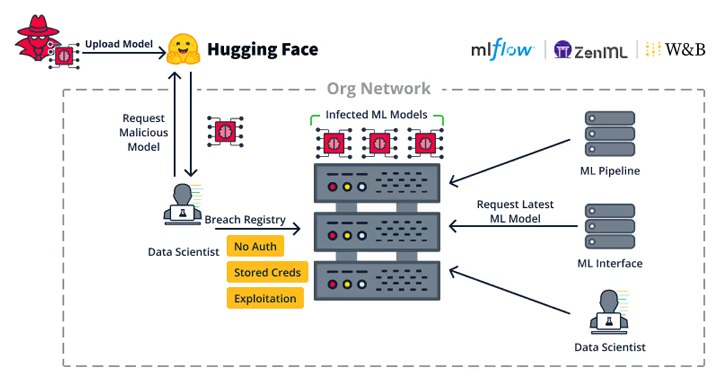
Les failles de sécurité dans les frameworks de machine learning peuvent prendre plusieurs formes. Les vulnérabilités détectées récemment permettent notamment à des attaquants de manipuler les modèles ML, d’accéder à des données sensibles et même de corrompre les résultats des modèles. En particulier, des failles dans des outils populaires comme TensorFlow, PyTorch, et Scikit-learn exposent des systèmes critiques aux cyberattaques.
Les vulnérabilités peuvent être exploitées de deux façons principales :
- Attaques par empoisonnement des données (Data Poisoning) : En modifiant les ensembles de données d’entraînement, les attaquants peuvent fausser les modèles en leur faisant apprendre des informations incorrectes, menant à des décisions erronées.
- Extraction de modèle (Model Extraction) : Les attaquants peuvent répliquer un modèle ML en lui soumettant de nombreuses requêtes. Cette technique leur permet de copier et de détourner un modèle sans avoir directement accès au code source ou aux données d’entraînement d’origine.
Pourquoi ces vulnérabilités posent-elles des risques majeurs ?
Le machine learning repose sur de vastes quantités de données, souvent personnelles ou sensibles. Lorsqu’un modèle ML est compromis, les conséquences peuvent être graves, notamment dans des secteurs critiques comme la santé, la finance et la sécurité publique. Voici quelques risques importants liés à ces failles de sécurité :
Atteinte à la confidentialité des données
Les frameworks ML manipulent d’énormes quantités de données pour entraîner leurs modèles. Ces données, souvent confidentielles, peuvent inclure des informations financières, médicales, ou personnelles. Les vulnérabilités découvertes permettent aux attaquants d’accéder à ces données, compromettant ainsi la confidentialité et exposant les utilisateurs à des risques d’usurpation d’identité ou de fraude.
Altération de l’intégrité des modèles
En manipulant les modèles via des attaques d’empoisonnement, les cybercriminels peuvent compromettre l’intégrité du modèle. Dans des cas où des modèles ML sont utilisés pour des recommandations financières, des diagnostics médicaux ou la détection de fraudes, de telles altérations peuvent avoir des conséquences graves, voire mettre en danger la sécurité des utilisateurs.
Déni de service (DoS) et sabotage opérationnel
Les attaquants peuvent également lancer des attaques de type déni de service (DoS) pour surcharger les ressources d’un modèle ML. En saturant le système, ils peuvent provoquer des ralentissements ou des interruptions, rendant le modèle indisponible pour les utilisateurs légitimes. Cela peut entraîner des pertes financières et une baisse de la fiabilité des systèmes.
Les techniques utilisées pour exploiter ces failles
Les chercheurs ont identifié plusieurs techniques que les attaquants emploient pour exploiter les failles de sécurité dans les frameworks ML.
Attaques par empoisonnement
L’empoisonnement des données est l’une des techniques les plus courantes pour manipuler un modèle ML. Dans ce cas, l’attaquant insère des données biaisées ou incorrectes dans l’ensemble de données d’entraînement. Ces données délibérément manipulées peuvent entraîner des comportements erronés du modèle. Par exemple, un modèle de détection de fraude pourrait être trompé pour classer des transactions frauduleuses comme légitimes, compromettant ainsi la sécurité du système.
Extraction de modèle
L’extraction de modèle permet à un attaquant de recréer un modèle sans y avoir directement accès. Cette technique repose sur l’envoi de nombreuses requêtes au modèle pour analyser ses réponses et ainsi reconstruire sa logique interne. Une fois le modèle répliqué, l’attaquant peut utiliser cette version détournée pour des activités illégales ou frauduleuses.
Attaques d’injection de commande
Les attaques d’injection de commande ciblent les processus d’entraînement du modèle. En insérant du code malveillant dans les ensembles de données ou dans les requêtes envoyées au modèle, l’attaquant peut exécuter des commandes non autorisées et prendre le contrôle du système. Ce type d’attaque est particulièrement dangereux car il peut affecter directement l’intégrité des infrastructures informatiques sous-jacentes.
Les secteurs les plus vulnérables
Bien que toutes les entreprises utilisant des frameworks ML soient exposées aux risques de sécurité, certains secteurs sont particulièrement vulnérables en raison de la nature des données manipulées ou de l’importance des décisions basées sur les modèles ML.
- Santé : Dans le secteur de la santé, les modèles ML sont utilisés pour des diagnostics médicaux, le suivi des patients et la gestion des dossiers. Une altération de ces modèles pourrait entraîner des diagnostics erronés, mettant en danger la vie des patients.
- Finance : Les institutions financières utilisent les modèles ML pour détecter les fraudes, analyser les risques et gérer les investissements. Toute faille de sécurité dans ces modèles pourrait conduire à des pertes financières importantes et à des fraudes.
- Industrie et production : Les industries qui dépendent des systèmes de maintenance prédictive et des chaînes de production automatisées utilisant des modèles ML sont également exposées. Une manipulation des données d’entraînement pourrait entraîner des défaillances dans les équipements, provoquant des interruptions de service coûteuses.
Comment renforcer la sécurité des frameworks ML ?
Face à ces vulnérabilités, les entreprises et les développeurs de modèles ML doivent prendre des mesures proactives pour améliorer la sécurité de leurs systèmes. Voici quelques stratégies efficaces pour se protéger contre les cyberattaques.
Surveillance des données d’entraînement
Il est crucial de surveiller la qualité des données d’entraînement et de mettre en place des contrôles pour éviter l’empoisonnement des données. En filtrant et en vérifiant les ensembles de données, les entreprises peuvent minimiser le risque de manipulation des modèles.
Utilisation de techniques de défense contre l’extraction de modèle
Les techniques de défense telles que le floutage des réponses et le brouillage de la sortie permettent de limiter les informations que le modèle fournit à chaque requête. Cela réduit la possibilité pour un attaquant de reconstituer la logique du modèle par extraction.
Authentification et contrôle d’accès renforcés
Pour empêcher les attaques d’injection de commande, les entreprises doivent mettre en place des mécanismes stricts de contrôle d’accès et d’authentification. Les processus d’entraînement et les interfaces doivent être sécurisés pour empêcher tout accès non autorisé.
Audit régulier des systèmes ML
Les audits de sécurité réguliers permettent d’identifier et de corriger les vulnérabilités. Ces audits incluent une évaluation des frameworks utilisés, la vérification de la robustesse des modèles, et l’analyse des comportements anormaux dans les réponses du modèle.



